10 причин раздражаться при использовании Apache Spark

Все больше и больше проектов уходит от поддержки парадигмы MapReduce на базе Hadoop и двигается в сторону нового кумира - Spark. Разработчики Mahout перестали воплощать новые алгоритмы машинного обучения на MR, обещая переехать в будущем на Spark Pipeline API. Наши любимые дистрибутивы от Cloudera и Hortonworks все больше и больше насыщаются инструментарием Spark.
Однако, из разных уголков мира Big Data слышны голоса скептиков, уже сделавших несколько проектов на Spark, тех первопроходцев, которые уже успели хлебнуть лиха на боевых проектах и теперь видят разницу между рекламными проспектами и суровой реальностью.
Итак, представляю вам попытку обобщить свой опыт и опыт коллег в разработке Java - приложений, работающих со Spark.

- Java API в долямбдовую эпоху
Если вы Java - разработчик, то вы с большой вероятностью начинали свои эксперименты со Spark, развернув виртуальную машину из какого-либо образа, вроде текущего HDP 2.3, на котором стоит Java 7 по умолчанию.
Java API для Spark в долямбдовую эпоху является калькой с такого же Scala API и требует довольно значительного количества анонимных классов с единственным методом, из - за чего становится затруднительно писать легко читающийся код.
До недавнего времени у вас могли случаться серьезные проблемы при попытке установки Java 8 и запуске заданий, написанных при помощи лямбд, однако теперь ситуация несколько выправляется, и через пару релизов HDP можно будет ожидать JDK 8 по умолчанию.
- Беспричинные остановки и неадекватные сообщения в логах
Ваш кластер может начать работать, писать в логи приятные вещи в течение дня, недели, месяца, года, а в один прекрасный день он замрет и остановится. И у вас должен быть запасной план на этот случай!
Нет, конечно, реальные причины обычно кроются где-то в логах, это может что-то вроде ошибок компрессии/декомпрессии во время стадии “перетасовки” [Shuffle]. Вы можете менять кодеки сжатия до посинения, но ловить потом эту ошибку снова и снова. При этом причина может лежать совсем на другом уровне, например на уровне версии ядра Linux машины с AWS.
Часто ошибка в логах уводит в сторону и является слишком высокоуровневой. Мониторьте все: сеть, диски, количество загруженных классов в JVM и вам воздастся!
- Проблемы с настройками по умолчанию
Помните, как всех раздражали настройки в Hadoop, когда нет единого рецепта и надо все время играть с количеством задач Map или Reduce, объемом памяти для их выполнения и т.д. Но они хотя бы адекватно работали при переходе от Single Server к MultiNode режиму.
Меняя режим кластера в Spark, вы получаете иную картину: в режиме Stanadalone у вас пытаются “скушать” всю память и все ядра, а запускаясь на Mezos, вы увидите как жалкие задачки Spark “откусят” у вас памяти с блошиную голову.
Конечно, это несложно поправить в конфигурационных файлах. Но поверьте, когда-нибудь наверняка вы забудете это сделать!
- Беспрестанный выпуск новых версий
Мы все радовались, когда вышла стабильная версия 1.0, хотя многие запускали в бой проекты на 0.7 - 0.9, и проекты работали.
Однако, в последнее время “те парни” зачастили с выпуском новых версий, и переход новых экспериментальных API в прочный кусок ядра ускорился, в связи с чем есть определенные сложности как с материалом для обучения, который устаревает за пару месяцев, так и с эффектом “откладывания” (давайте подождем следующей версии, тогда и напишем систему, там будут такие вкусные фичи, мммм).
В итоге создается нездоровая ситуация, когда ребята, вчера скачавшие Spark, смотрят свысока на парня, сделавшего за последний год 2-3 боевых проекта. Хуже дела обстоят только в мире MVC Javascript - фреймворков.
Мне кажется, должно пройти определенное время, чтобы говорить о выходе Spark на определенное плато развития, и только тогда можно будет вкладываться в обучение ваших сотрудников данной технологии, а пока имеет смысл брать в разработку версии двух-, трехмесячной давности.
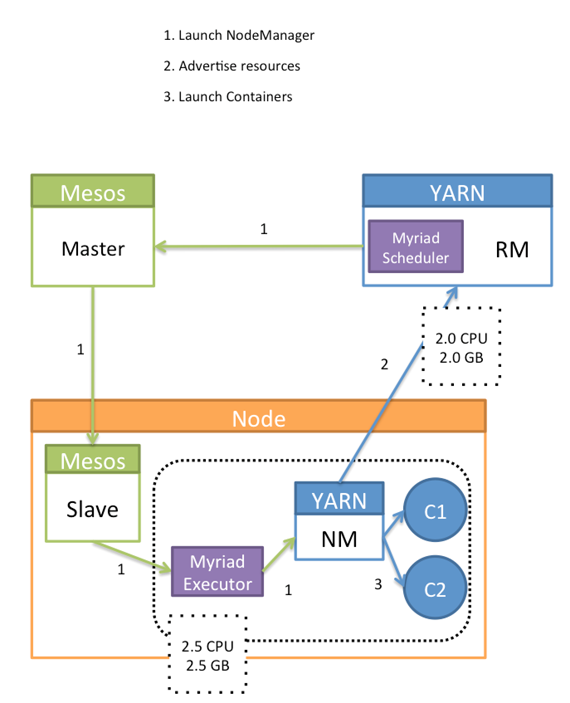
- Постоянные споры Mezos vs Yarn
Выбор между Mezos и Yarn для кластера - весьма распространенное заблуждение в проектных командах. Но проблемы выбора на самом деле нет!
Многие забывают, что Yarn был создан как распорядитель ресурсов именно для Hadoop, для обслуживания пакетных заданий с длительным временем исполнения, тогда как Mezos создавался как подобие операционной системы с ее обслуживанием коротких маленьких разнообразных заданий, прилетающих в любой момент времени.
Кроме этого, существуют архитектуры датацентров, где Mezos управляет ресурсами в целом, а YARN ответственен за выполнение Hadoop-заданий. Таким образом, каждый играет свою роль, и при этом делает это великолепно.
- GC для большого куска памяти
На каких JVM запускаете свой Spark вы? Корректно ли ведет себя стандартный HotSpot Garbage Collector на 100 Гб памяти? Не вносят ли паузы значительный вклад во время ожидание ответа от кластера?
Этих вопросов мы почти не касались в классической Hadoop - архитектуре c сотнями маленьких “машинок” с жалкими 2 - 4 Гб оперативной памяти.
Spark подарил нам возможность запускать кластера дорогих больших машин, а вместе с этим вернул нас на землю к необходимости знать и понимать алгоритмы работы GC.
Пока еще слишком мало данных, чтобы говорить о каком-то фаворите, но в моем личном рейтинге лидируют G1 и изменение параметра spark.storage.memoryFraction.
- Python для отстающих
До определенного момента (начала 2015 года) была характерна следующая ситуация: поддержка новых возможностей Spark для Python API выходила с определенной задержкой, да и вообще в BigData - сообществе существовало предубеждение против Python - разработчиков, мол нечего с ними делиться куском пирога, пусть учат Java.
Но все возрастающая популярность построения моделей машинного обучения на Python при помощи Sckit-learn/Pandas/NumPy - библиотек изменила ситуацию в считанные месяцы.
Мы дали питонистам в руки мощное оружие! Поглядите только на этот пример с kMeans. Да как они посмели заставлять MLlib выполнять для них распределенные вычисления на Spark - кластере?!!! В общем, ребята наступают нам пятки.

- Необходимость миграции с Hadoop на Spark
Все мы знаем простую истину: “Работает - не трогай!”
Но всегда появляется герой, который, наслушавшись маркетологической лапши, отправляется сносить Hadoop и переписывать MR-задачи на Spark API и RDD - коллекции, не считаясь со временем и потерями, потому что “Hadoop - старье, на нем пишут только дедули”. Но “дедули” уже затюнили донельзя боевое решение, и боевое решение работает, чего нельзя сказать о новой системе аналитики, которую еще предстоит написать, и не факт, что вы получите на ваших моделях данных 50x прирост скорости.
Для новых решений становится общим местом выбирать Spark, для старых - стоит развернуть Spark-тень над копией данных (не в коем случае не над одной и той же HDFS) и замерить, стоит ли овчинка выделки.
- Вампир Scala начинает потихоньку пить кровь
Если Hadoop с самого начала утверждал ведущую роль Java и даже позволял нам, разработчикам, тихо гордиться таким флагманом экосистемы, задирая нос перед Python или Ruby - разработчиками, то Spark с самого начала во всех видеоуроках и документации, во всех презентациях и книгах подталкивает нас к изучению Scala.
Вы видите код на Scala, вы запускаете легкие примеры в Scala REPL, вы пишите свои первые трансформации в Pipeline - стиле, и все - коготок у птички уже увяз.

Хорошо это или плохо для Java - разработчика? Для разработчика это плохо лишь тем, что у вас с некоторой повышенной вероятностью может развиться болезнь оболочек мозга - Javaphobia. Для руководителя разработки это чревато потерей примерного JEE-бойца, который может начать требовать проектов на Scala, а их у компании может не оказаться.
- Unsafe Spark
Горячим хитом этого лета в Java - сообществе стало обсуждение давно грядущего изменения/закрытия приватного API в JDK, знаменитого пакета Unsafe, позволяющего напрямую производить операции в памяти в духе C++. Как известно, sun.misc.Unsafe используется во многих популярных поделках, вроде Cassandra, Hadoop, Spring.

Не избежал подобной участи и Spark. В классе Platform мы можем видеть вполне типичное использование методов класса Unsafe.
К концу осени уже появились наметки по выходу из “UnsafeCrisis”, но это вселяет определенную нервозность как в наших заказчиков, так и в разработчиков, активно оптимизирующих работу с памятью.
Подводя итоги...
Конечно, это отнюдь не полный перечень причин, которые нас с вами заставляют изрядно раздражаться при длительном использование Spark на проектах, однако они же и показывают, что в мире BigData еще не сказано последнее слово и не наступил “конец истории”.
В рамках Spark или в рамках других проектов все текущие вопросы будут разрешены, но обязательно появятся новые и так до скончания века. А мы будем искать свой священный Грааль для анализа данных и далее.

Комментарии
Отправить комментарий